What is Random F data?
Random F Data generates values from the F-distribution a right-skewed, always-positive distribution defined by two degrees of freedom parameters (numerator df and denominator df). The F-distribution arises naturally when comparing two variances or evaluating ANOVA and regression F-statistics.
Simple Definitions: Generates random values from the F-distribution used for validating variance comparisons, ANOVA outputs, and regression F-statistics.
When to use Random F data?
- Use to validate ANOVA and regression analyses with known F-distribution properties.
- Use in power analysis simulations to estimate sample size for variance comparison studies.
- Use for educational demonstrations of how F-distributions change with different degrees of freedom.
Guidelines for correct usage of Random F data
- Specify both numerator and denominator degrees of freedom correctly they significantly change the distribution shape.
- F-values are always non-negative.
Alternatives: When not to use Random F data
- For normally distributed t-test simulations, use Random Normal Data
- For t-statistic simulations, use Random T Data
Example of Random F data
The following steps to Generate Random F data:
- To Generate Random F data need to fill the required options.
- Now analyses the data with the help of https://qtools.zometric.com/ or https://intelliqs.zometric.com/.
- To find Random F data choose https://intelliqs.zometric.com/> Statistical module> Random Data > Random F data
4. After using the above mentioned tool, fetches the output as follows:
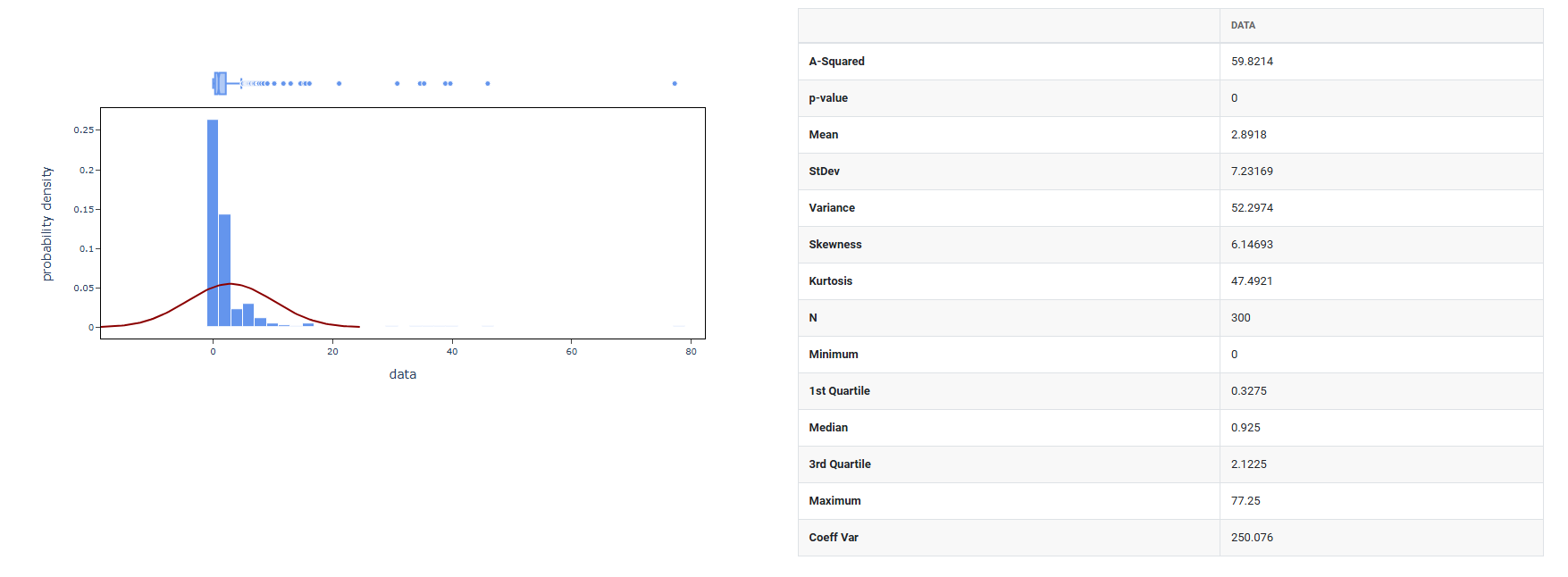

How to do Random F data
The guide is as follows:
- Login in to QTools account with the help of https://qtools.zometric.com/ or https://intelliqs.zometric.com/
- On the home page, choose Statistical Tool> Random Data>Random F data.
- Next, you need to fill the required options.
- Finally, click on calculate at the bottom of the page and you will get desired results.
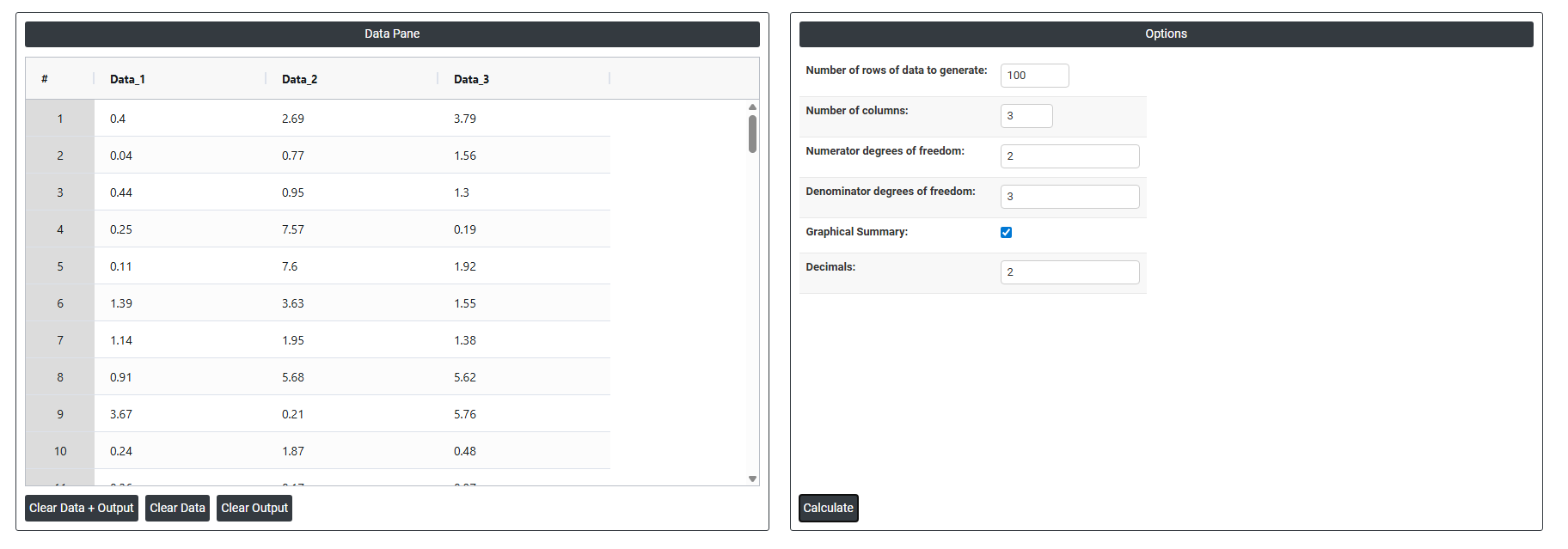
On the dashboard of Random F data, the window is separated into two parts.
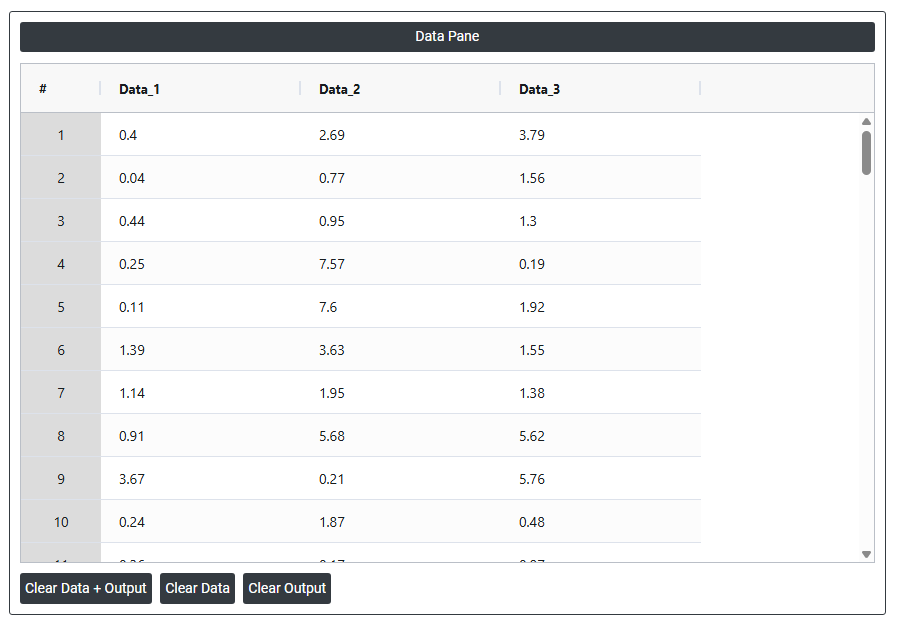
On the left part, Data Pane is present. In the Data Pane, each row makes random data generated. Data will be generated after filling the required options.
On the right part, there are many options present as follows:
- Number of rows of data to generate: Specifies how many random data points to generate. For example, entering 10 will produce exactly 10 rows of random values, all visible in the data pane.
- Number of columns: Specifies how many variables (columns) each row will have. For example, entering 3 will produce 3 columns of randomly generated data side by side in the data pane.
- Numerator degrees of freedom: The first shape parameter of the F distribution, corresponding to the degrees of freedom of the variance in the numerator. It controls the overall shape of the generated distribution. For example, entering 2 will generate random F values based on a numerator with 2 degrees of freedom.
- Denominator degrees of freedom: The second shape parameter of the F distribution, corresponding to the degrees of freedom of the variance in the denominator. Together with the numerator degrees of freedom, it fully defines the shape of the F distribution from which the random data is generated. Larger values here cause the distribution to become more symmetric and closer to a normal shape.
- Graphical summary: After the random data is generated using the mean and standard deviation you specified, this option produces a graphical analysis of that data such as a histogram showing how the generated values are distributed. It is a visual result based on the data that was just created.
- Decimals: Controls the number of decimal places in the generated random values themselves. For example, setting it to 2 means every generated number will be rounded to 2 decimal places, like 47.83 or 52.16. Setting it to 0 produces whole numbers only.