
One sample t test
A one-sample t-test is a statistical test used to estimate the mean of a population and compare it to a target or reference value when the population standard deviation is unknown. This parametric test determines if there is a significant difference between the sample mean and a hypothesized population mean.
Last reviewed
Key takeaway
A one-sample t-test is a statistical test used to estimate the mean of a population and compare it to a target or reference value when the population standard deviation…
On this page
What is One Sample t test?
A one-sample t-test is a statistical test used to estimate the mean of a population and compare it to a target or reference value when the population standard deviation is unknown. This parametric test determines if there is a significant difference between the sample mean and a hypothesized population mean. The one-sample t-test also calculates a confidence interval for the population mean, providing a range of values likely to include the true mean. This analysis is particularly useful for small sample sizes or when the population variance is not known.
When to use One Sample t test?
The one-sample t-test is appropriate when the following conditions are met:
- The sample is randomly selected from the population of interest.
- The data are normally distributed.
- The population standard deviation is unknown, but can be estimated from the sample.
- The sample size is sufficiently large (typically, n > 30) to ensure that the sampling distribution of the mean is approximately normal.
Examples of when to use a one-sample t-test include:
- A researcher wants to test whether the average height of a sample of students is the same as the average height of students in the general population.
- A company wants to test whether the average time it takes to complete a task is the same as the industry standard.
- A doctor wants to test whether a new drug has a significant effect on reducing blood pressure in patients.
Overall, the one-sample t-test is a powerful statistical tool that can help researchers draw conclusions about populations based on a single sample.
Guidelines for correct usage of One sample t test
- Use One sample z if you know the population standard deviation.
- Use continuous data for the analysis, such as weights of packages.
- Use One sample Poisson Rate if the data contain counts, and One Proportion if data classify into two categories.
- Sample size should be greater than 20 and not severely skewed for appropriate hypothesis testing.
- Collect random samples to make inferences about the population.
- Paired t-test should be used for dependent or paired data.
- Sample size should be large enough for precise estimates, narrow confidence intervals, and protection against errors. Use Power and Sample Size for one Sample t to determine the appropriate sample size.
Alternatives: When not to use One sample t test
- If the standard deviation of the population is known, it is recommended to use One sample z instead of t-test since the former has higher power than the latter.
Example of One sample t test?
An economist collects data on the monthly energy cost for 25 families in the current year to determine if there has been a change from the previous year when the mean cost was $200. They perform a One sample t test to test if the current year's energy cost is significantly different from $200. The test in following steps:
- Gathered the necessary data.
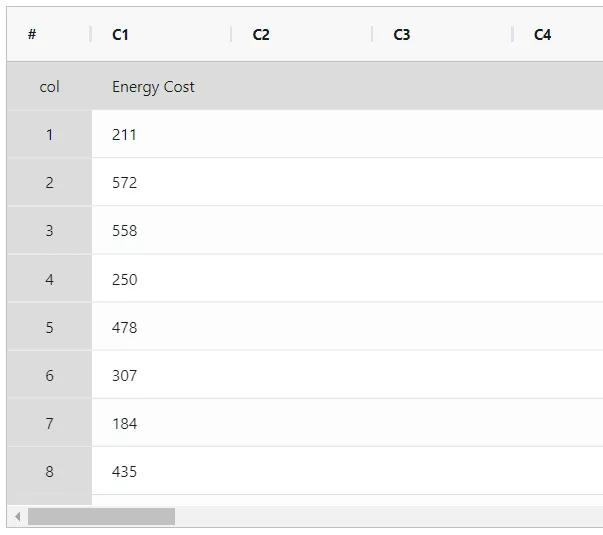
- Now analyses the data with the help of https://qtools.zometric.com/ or https://intelliqs.zometric.com/.
- To find One sample t-test choose https://intelliqs.zometric.com/> Statistical module> Graphical analysis> One sample t-test.
- Inside the tool, feeds the data along with other inputs as follows:
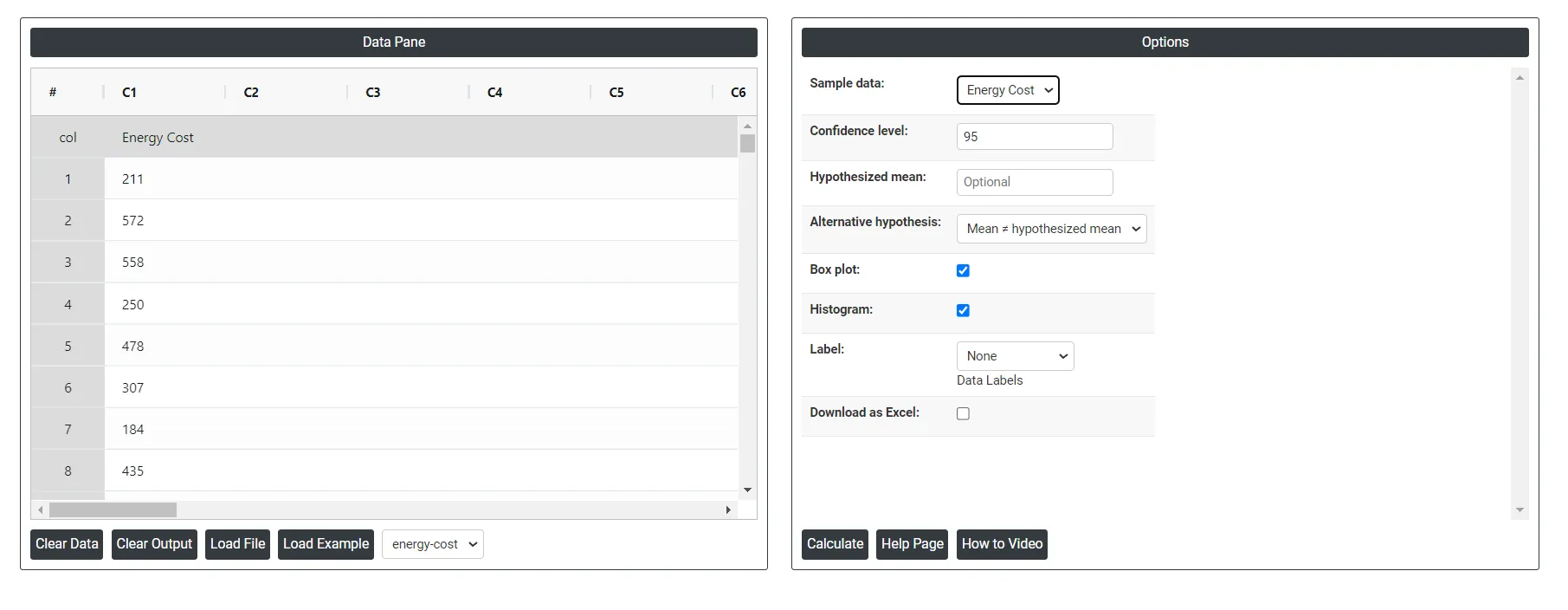
5. After using the above mentioned tool, fetches the output as follows:
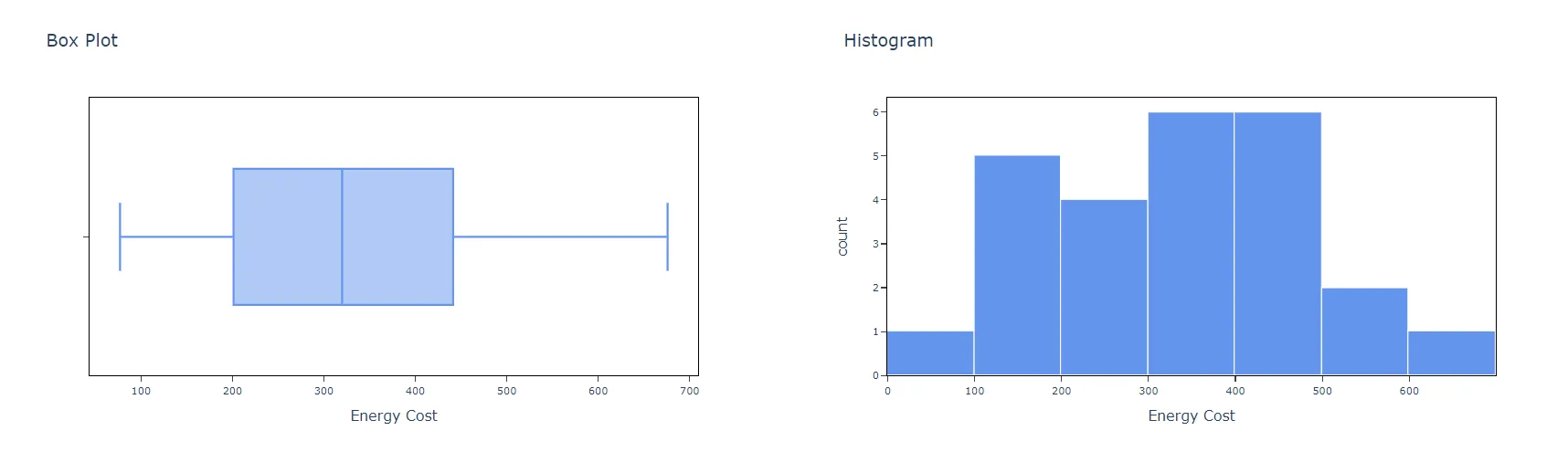
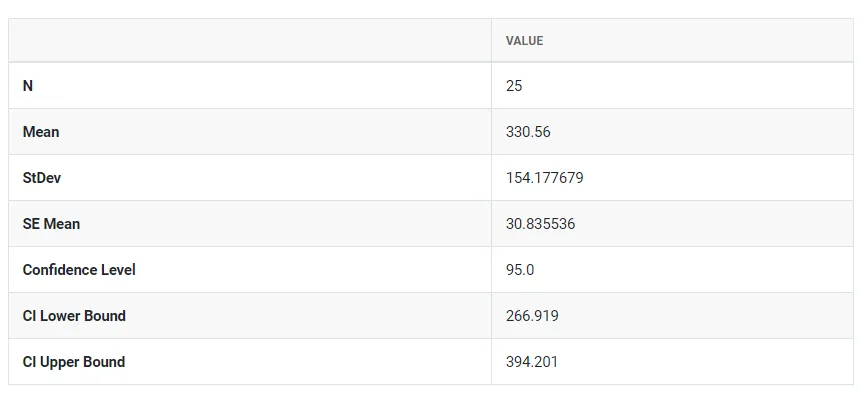
How to do One sample t test
The guide is as follows:
- Login in to QTools account with the help of https://qtools.zometric.com/ or https://intelliqs.zometric.com/
- On the home page, choose Statistical Tool> Graphical analysis >One sample t test .
- Click on One sample t test and reach the dashboard.
- Next, update the data manually or can completely copy (Ctrl+C) the data from excel sheet and paste (Ctrl+V) it here.
- Next, you need to put the values of confidence level and hypothesized mean.
- Finally, click on calculate at the bottom of the page and you will get desired results.
On the dashboard of One sample t test, the window is separated into two parts.
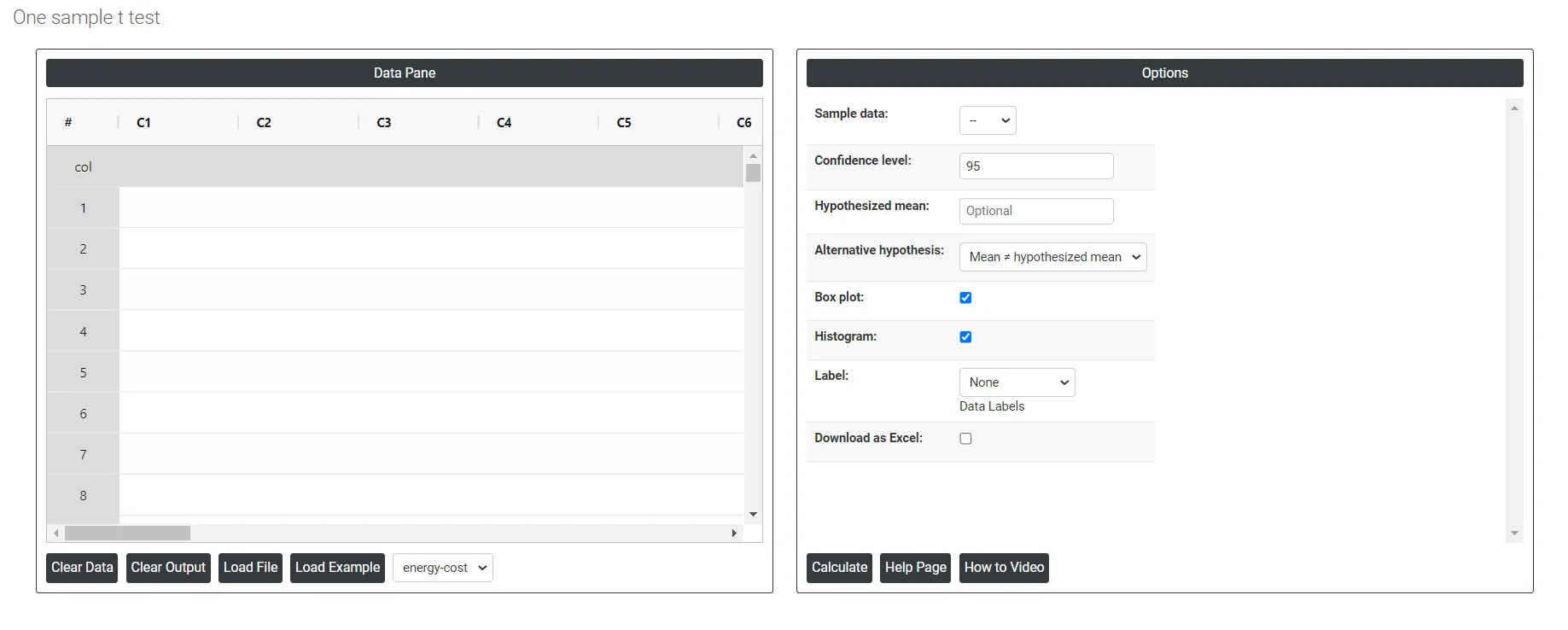
On the left part, Data Pane is present. In the Data Pane, each row makes one subgroup. Data can be fed manually or the one can completely copy (Ctrl+C) the data from excel sheet and paste (Ctrl+V) it here.
Load example: Sample data will be loaded.
Load File: It is used to directly load the excel data.
On the right part, there are many options present as follows:
- Confidence level: In hypothesis testing, the confidence level represents the degree of certainty or level of confidence that we have in our statistical analysis. It is a probability value that indicates the likelihood that the true population parameter falls within the specified range of values.Typically, the confidence level is expressed as a percentage and is denoted by (1 - α), where α is the level of significance or the probability of rejecting a true null hypothesis. For example, if we have a confidence level of 95%, then we are saying that we are 95% confident that the true population parameter lies within our interval estimate, and there is a 5% chance of making a type I error (rejecting a true null hypothesis). In practical terms, a higher confidence level means that we are more confident in our statistical analysis and results. However, increasing the confidence level also increases the width of the confidence interval, making it more difficult to detect small effects. Therefore, the choice of the confidence level depends on the context of the study and the goals of the researcher.
- Known standard deviation: In hypothesis testing, the standard deviation is a measure of the spread of a set of data around its mean. It is used in conjunction with the sample mean to calculate the test statistic, which is then used to determine the p-value of a hypothesis test. The standard deviation of a sample is denoted by the symbol s, and it is calculated as the square root of the sample variance. The sample variance is the average of the squared differences of each observation from the sample mean. In hypothesis testing, the standard deviation is used to determine the significance of the difference between the observed sample mean and the expected population mean under the null hypothesis. Specifically, the test statistic (usually denoted by t) is calculated as the difference between the sample mean and the population mean (assumed under the null hypothesis), divided by the standard error of the mean (which is equal to the standard deviation of the sample divided by the square root of the sample size).
- Hypothesized mean: The hypothesized mean, also known as the expected mean or population mean, is a value specified in the null hypothesis that represents the average value of the variable being tested. It is a theoretical value that is used to compare the actual sample mean to determine whether the difference is statistically significant or due to chance.
- Alternative hypothesis: In hypothesis testing, the alternative hypothesis (also called the research hypothesis) is a statement that represents a different conclusion than the null hypothesis. The null hypothesis typically represents the status quo or the assumption that there is no significant difference or relationship between two or more groups or variables. The alternative hypothesis is the statement that is being tested, and it proposes that there is a significant difference or relationship between the groups or variables being studied.
- Box Plot: Check in will provide you box plot chart or else not.
- Histogram: Check in will provide you histogram chart or else not.
- Label: This will do the data labels, which contains three options:
- Outlier: Data values that are far away from other data values, can strongly affect your results.
- All quartiles: Quartiles are values that divide a sample of data into four equal parts. Quickly evaluate a data set's spread and central tendency.
- Mean: The mean in a box plot to provide additional information about the data's central tendency.
- Individual Data: An individual data point is a single observation or value in a dataset.
- Download as Excel: This will display the result in an Excel format, which can be easily edited and reloaded for calculations using the load file option.
How to do One sample t test for summarized data
The guide is as follows:
- Login in to QTools account with the help of https://qtools.zometric.com/ or https://intelliqs.zometric.com/
- On the home page, choose Statistical Tool> Graphical analysis >One sample t test for summarized data
- Click on One sample t test for summarized data and reach the dashboard.
- Next, update the data manually or can completely copy (Ctrl+C) the data from excel sheet and paste (Ctrl+V) it here.
- Next, you need to put the values of sample size, sample mean, standard deviation, hypothesized mean and confidence level.
- Finally, click on calculate at the bottom of the page and you will get desired results.
On the dashboard of One sample t test for summarized data, the window has only left portion.
Load File: It is used to directly load the excel data.
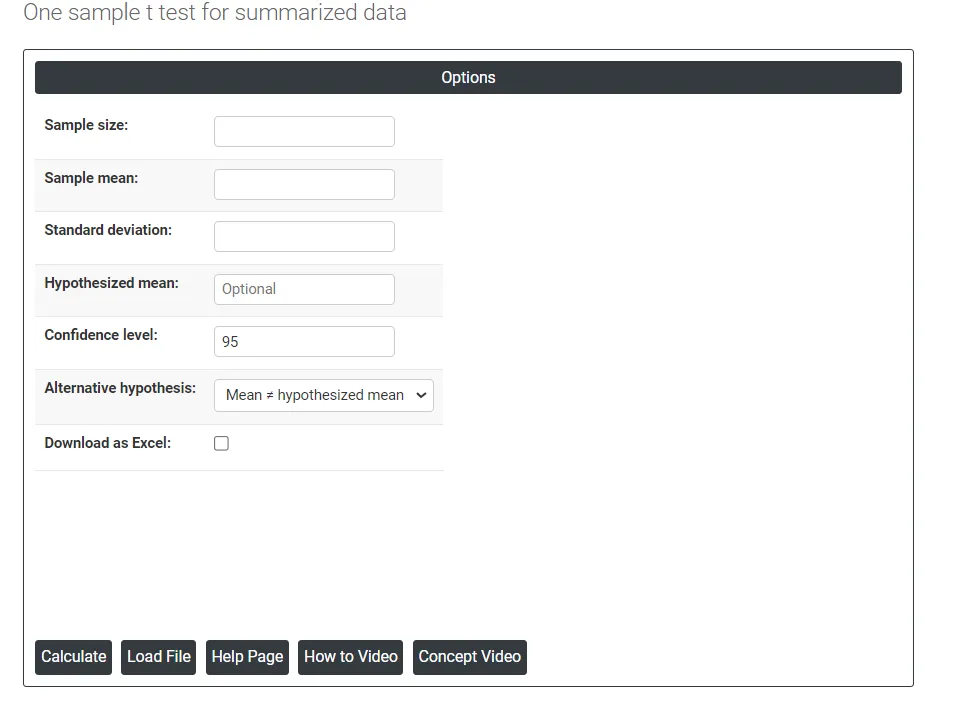
On the left part there are many options present as follows:
- Sample size: Sample size refers to the number of individuals, objects, or events selected from a population to be studied in order to draw conclusions about the whole population. In other words, it is the number of observations or participants included in a study. The size of the sample can have a significant impact on the accuracy and reliability of the study's results. A larger sample size typically provides a more representative picture of the population and helps to reduce the effects of random sampling error. Therefore, it is important to determine an appropriate sample size before conducting research to ensure that the results are statistically valid and reliable.
- Sample mean: The sample mean is the average value of a set of observations or data points selected from a larger population. It is calculated by adding up all the values in the sample and dividing by the number of observations. The sample mean is often used as an estimator of the population mean, which is the average value of the entire population.
- Standard deviation: In hypothesis testing, the standard deviation is a measure of the variability of the data. It is often used in conjunction with the mean to assess whether the observed difference between two groups is statistically significant.
- Hypothesized mean: The hypothesized mean, also known as the expected mean or population mean, is a value specified in the null hypothesis that represents the average value of the variable being tested. It is a theoretical value that is used to compare the actual sample mean to determine whether the difference is statistically significant or due to chance.
- Confidence level: In hypothesis testing, the confidence level represents the degree of certainty or level of confidence that we have in our statistical analysis. It is a probability value that indicates the likelihood that the true population parameter falls within the specified range of values.Typically, the confidence level is expressed as a percentage and is denoted by (1 - α), where α is the level of significance or the probability of rejecting a true null hypothesis. For example, if we have a confidence level of 95%, then we are saying that we are 95% confident that the true population parameter lies within our interval estimate, and there is a 5% chance of making a type I error (rejecting a true null hypothesis).In practical terms, a higher confidence level means that we are more confident in our statistical analysis and results. However, increasing the confidence level also increases the width of the confidence interval, making it more difficult to detect small effects. Therefore, the choice of the confidence level depends on the context of the study and the goals of the researcher.
- Download as Excel: This will display the result in an Excel format, which can be easily edited and reloaded for calculations using the load file option.